

GPT-3 and the Writing on the Wall
GPT-3 and the Writing on the Wall
Demand drivers for Semiconductors
I'm sure you've read about GPT-3 before if you are interested enough to click on this link. For the sake of this article, I'm going to assume you're decently familiar with the discussion regarding GPT-3 making the internet rounds as of late. I'll have some of the ones I find interesting in an endnote below.
I am not qualified to know if this is truly the way forward, or if it's just another pit stop on the long road forward in AI research. But the thing I found most interesting from the discussion was the paper published by Open AI, “Scaling Laws for Neural Language Models” and the estimates of how much compute it took to train GPT-3. The most interesting conclusion from an investor’s viewpoint is not GPT-3, but the writing on the wall. Let’s discuss this.
Scaling Laws and GPT-3
Many types of AI models seem to do much better at scale. This paper discusses this and makes a few broad conclusions which I summarized below.
1. Performance depends strongly on scale

2. In order to scale, Models must scale with the number of parameters, data-set size, and compute
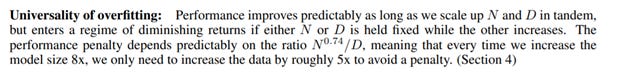
3. It is likely that the performance benefits will still follow the relationship found for several orders of magnitude more
After this paper, the implication is that pursuing much larger models seems to make sense. It’s likely that we will see in the coming years what the upper bound of this observed scaling relationship is.
The Big Picture - Bigger, Faster, Better
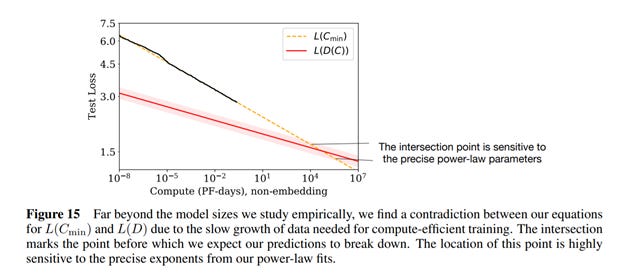
I think a much easier way to frame this is in terms of the Open AI piece on AI and Compute density that applies broadly to more than just GPT-3. This is the graph below, which notes that AI compute intensity is doubling every ~3.4 months, while historical Moore’s law is every 2 years. It’s worth a read – but I thought I would update the graph (approximately, sorry I can’t get the dataset!). It’s a much simpler way to wrap your mind around the computing needs of AI models.
The red dot is GPT-3 based on their paper, at approximately ~3624 petaflop/s-days.
The law is alive and well, and a clear doubling of the models before it. In my view, it is reasonable to expect us to see much larger models very soon. What is stopping GAFAM from pushing a magnitude larger model today, especially with you can argue that some of their business models are at risk?
In fact – this piece has an interesting take. What is to stop companies with the most capital in the world from pushing ahead at a scale that no others can achieve, and create new markets while others struggle to spend the requisite hundreds of millions of dollars to train models?
In particular, the cloud titans (AWS, Azure, GCP) look best situated here. Not only do they sell compute on-demand to customers for healthy profits (~30% EBIT margins in the case of AWS), but also they can use said profits to reinvest in compute capacity unlike anyone else. And the excess compute accrues to them. There is likely a reason the two major smart speaker companies both have their own public cloud platforms; excess compute can subsidize Alexa/Google’s speaker needs. But they are going to need a lot more compute. And that’s because of the slowing of Moore’s.
The Compute Conundrum
Let’s first state the obvious: training large models are really expensive. Some estimates of GPT-3 training is being put at ~$5 million for one-time training in pure compute cost and another $10 million in salaries. Now I can assure you they didn’t train it once, so it’s likely a few multiples higher than that price tag if you pay from the perspective of renting cloud GPUs. It is likely that if you’re serious about training, you’re probably not renting cloud GPUs, but that’s another conversation.
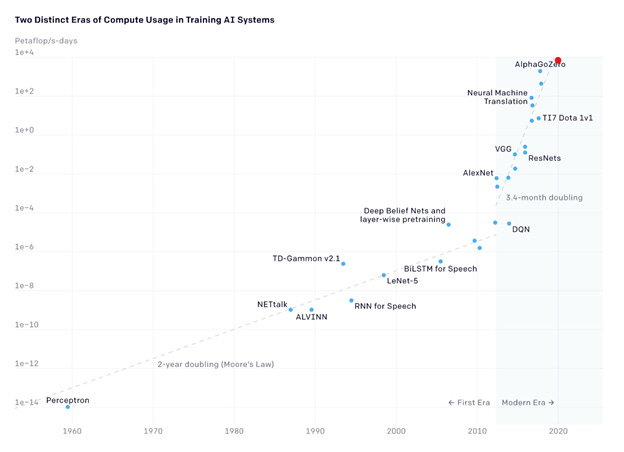
But the thing that is really exciting (or frightening if you’re spending the money) is it looks like your cost of training is likely going to grow much faster in the future. Because as we discussed that models of the future will be many times larger in terms of compute, data, and parameters, the semiconductors of the future are hitting the wall of Moore’s law hard. The traditional Moore’s law of geometry shrink and power scaling is dead. I’ve written briefly about it in the past and argued that the way forward is specialization, but even then there is likely a wall there.
What I’m trying to get at is the steady cadence of geometry shrink is slowing, and it’s happening just as the demand is ballooning in a new way. While demand has been anticipated by the industry for a long time, I don’t believe semiconductors will be able to keep up if we truly pursue a maximalist AI future. Even with the creative toolkit of “More than Moore”, bit growth and importantly $ per FLOP growth should not be able to keep up. And so it’s time to look at the wall.
What is the Writing on the Wall?
Let’s make it simple. The paragraph on scaling laws briefly talks about demand, the paragraph on “the compute conundrum” talks briefly about supply. Let’s abstract it and take this year’s current amount of semiconductor compute consumed, multiply it by the next 5 years demand growth, divide it by supply growth, and that is the future compute consumed.
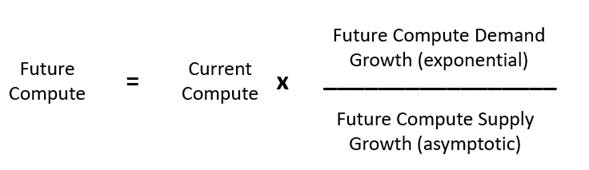
Now, this is in vague units, but if per unit supply growth is slowing, the implication is this means a lot more semiconductors. If scaling for scale’s sake becomes the predominant meta in AI research, I cannot think of a bigger demand shock. The writing on the wall is orders of magnitude more compute purchased. And this won’t be your parent’s x86, but GPUs, DPUs, SmartNICs, memory, and likely new form factors we haven’t thought of yet.
But luckily this take is pretty lukewarm. Semiconductors as a percentage of GDP have only gone one way our entire lives. And I think the increasing capital intensity of compute-heavy activities such as GPT-3 and the larger models to come is just further proof of the bull case. Semiconductor sales just got an identifiable demand driver going forward, and should accelerate in dollar terms into the coming decade. I see nothing stopping semiconductors as a percentage of GDP to more than 1%+ in the coming decade.
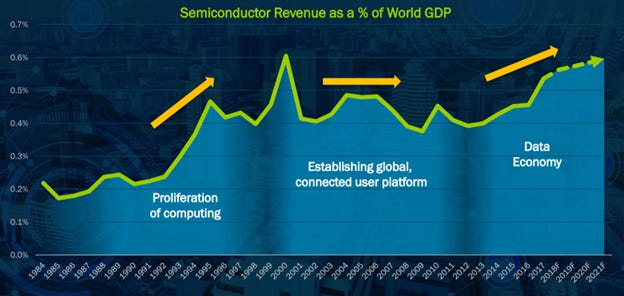
Source: 2018 Lam Research Investor Day
So, Who Benefits from the Writing on the Wall?
First, let’s address one of the worst takes, it’s not Intel. Habana and Nervana maybe, but this will not move their x86 franchise. Intel will not meaningfully benefit from incremental demand. x86 is just not going to be in the driver seat of AI/ML. Fast sequential speed is kind of pointless, and the key here is massive parallel computation. I think this is best captured in this goofy but appropriate metaphor of painting the Mona Lisa with paint guns.
Of course, Nvidia sponsored this. Which brings me to my first beneficiary, team green. As it stands, I believe that Nvidia is the single purest publically traded play and beneficiary. In conjunction with the GPT-3 scaling hype, the recent Ampere release which was completely focused on the data center, and the shifting narrative towards AI training, Nvidia is clearly front and center.

Their staggering recent multiple expansion might now make more sense if you are expecting a multiple-year demand shock. I want to write more about them in the future, as I believe their opinionated software and turnkey ecosystem makes them the easiest silicon partner. The benefits of this integration cannot be overstated, but we will discuss this another time.
To a lesser extent the other big graphics card provider, AMD should benefit. But the reason why I don’t think it’s their market to win is the SDK and software support for ML focused activities at AMD meaningfully trails Nvidia. They already have another war to win with x86 in the data center from one of the largest semiconductor revenue pools in existence.
The next type of player who should benefit but I constantly question is the FPGA accelerators (XLNX, Intel’s Alterra, LSCC, MCHP’s segment). If you’d believe Xilinx management, their new SDKs and large throughput are a perfect fit for acceleration! But I am doubtful, as FPGA’s always seem to be the compute of the future. And may always stay that way. Verilog (the historical language of FPGAs) is a nightmare to program in, and even with new python and C++ support, the reputation of Verilog is hard to shake and will keep many away.
I am of the belief that the best way is de novo, and many of the private companies that have shown fancy new architectures that have large in-memory compute come to mind. In no order Cerebras, Groq, Habana (RIP), and the tail of other startups that are attacking this hard problem seem well equipped. It’s a bit early to know who “wins”, but these are ones to watch. Hopefully, they will pursue going public in the coming years.
It takes a village of semiconductors to train a large model, and what I have described above is the puts and takes of accelerators. There is a whole other problem that is unmentioned, and that is the bottleneck. Almost all HPC/ML projects are not limited by compute but by input and output speeds (I/O). Here the remedy is clear, a lot more memory at the fastest speeds, meaning DRAM and NAND. If you look at most of the specs of the new AI-focused SKUs, often they have been growing memory at very large rates. I believe that the memory players (MU/Samsung/SK Hynix) are well-positioned from this perspective.
Thanks for reading! If you found this useful, please share it. Until next time.
Disclaimer: I will qualify this post with a statement. I am not an expert in AI/ML/what have you. I cannot be 100% certain about some of the statements other experts are making are certain. I draw conclusions and potential conclusions from others, and if they are wrong, then I'm wrong. Nothing written here is investment advice or should be construed as investment advice.
Appendices - GPT-3 articles I thought were interesting
https://www.gwern.net/newsletter/2020/05#gpt-3
https://a16z.com/2020/07/29/16mins-gpt3-natural-language-neural-net-deep-learning-few-shot-zero-shot/
https://arxiv.org/pdf/2001.08361.pdf
https://arxiv.org/pdf/2005.14165.pdft
Appendix: Quick Observation on GAFAM

Something to note is that GAFAM is becoming more capital intensive. And no, Amazon does not include capital leases. This is simple Capex for the sake of brevity. Apple is also the least capital intensive and serves an interesting foil for the others, who are pursuing the maximal AI dream. But I believe that the businesses are all going to increase in capital intensity into the future, and in recent years have already started to reflect that. Going forward these are the Capex budgets that are likely to reflect the pursuit and should be going up.
Any chance you could do a post about the companies other than NVDA levered to the AI theme?